
Migration
Welche gillt es zu Beachten und welche Möglichkeiten gibt es bei Datenmigrationen
Was ist eine Migration ?
Eine Migration bezeichnet den Prozess, bei dem Daten, Systeme oder Anwendungen von einer Plattform oder Umgebung in eine andere übertragen werden. Dieser Prozess dient dazu, neuere oder bessere Technologien einzuführen, die Verfügbarkeit und Performance zu verbessern oder die Kosten zu reduzieren.
Eine Migration kann sowohl innerhalb eines Unternehmens als auch zwischen Unternehmen durchgeführt werden. In der IT-Branche werden oft Datenmigrationen von einem Datenbanksystem in ein anderes oder von einer Anwendungsumgebung in eine Cloud-basierte Umgebung durchgeführt.
Eine Migration kann auch beinhalten, dass bestehende Daten und Systeme angepasst oder konvertiert werden müssen, um mit der neuen Umgebung kompatibel zu sein.
Zusammenfassend kann man sagen, dass eine Migration ein wichtiger Prozess in der IT-Branche ist, um neue Technologien einzuführen, die Verfügbarkeit und Performance zu verbessern oder die Kosten zu reduzieren.
Was muss man bei einer Datenmigration beachten ?
Bei einer Datenmigration gibt es einige wichtige Faktoren, die man beachten sollte, um einen erfolgreichen Übergang zu gewährleisten:
Datenqualität: Überprüfen Sie die Qualität der Daten, die migriert werden sollen, und bereinigen Sie sie, wenn notwendig. Dies hilft, Fehler bei der Übertragung zu vermeiden und sicherzustellen, dass alle Daten korrekt und vollständig sind.
Zieldatenbank: Überprüfen Sie die Zieldatenbank, um sicherzustellen, dass sie alle erforderlichen Funktionen und Datenmodelle unterstützt.
Zeitplan: Legen Sie einen Zeitplan für die Migration fest, einschließlich Zeiten für die Datenbereinigung, Übertragung und Überprüfung.
Dokumentation: Dokumentieren Sie alle Schritte der Migration, einschließlich der verwendeten Werkzeuge und Skripte.
Datensicherheit: Überprüfen Sie die Datensicherheit und stellen Sie sicher, dass alle sensiblen Daten geschützt sind.
Testen und Überwachen: Testen Sie die migrierten Daten und überwachen Sie den Übergang, um sicherzustellen, dass alle Daten korrekt und vollständig übertragen werden.
Überprüfung: Überprüfen Sie alle migrierten Daten, um sicherzustellen, dass sie korrekt und vollständig sind.
Wenn diese Schritte sorgfältig beachtet werden, kann eine Datenmigration erfolgreich und ohne Datenverlust durchgeführt werden.
Was ist der Unterschied zwischen einer Datenmigration und einer Datenkonvertierung ?
Die Datenmigration bezieht sich auf den Prozess des Übertragens von Daten von einer Quelle zu einem Ziel, während die Datenkonvertierung sich auf den Prozess des Änderns des Formats oder der Struktur der Daten bezieht. Im Allgemeinen ist eine Datenmigration ein umfassenderer Prozess, der oft eine Datenkonvertierung beinhaltet, um die Daten in das Zielformat zu übertragen.
Wie kann man die Datenintegrität bei einer Migration sicherstellen ?
Die folgenden Punkte sind bei einer Datenmigration zu beachten :
Vorbereitende Analyse: Überprüfen Sie die Datenquellen auf Vollständigkeit, Richtigkeit und Konsistenz, bevor Sie mit der Migration beginnen.
Mapping und Übersetzung: Definieren Sie das Mapping zwischen den Datenfeldern in der Quelle und dem Ziel und übersetzen Sie diese entsprechend.
Validierung und Überprüfung: Führen Sie Tests durch, um sicherzustellen, dass die Daten während der Migration korrekt übertragen werden und dass das Zielformat die erwarteten Daten enthält.
Backup und Wiederherstellung: Stellen Sie sicher, dass Sie ein Backup Ihrer Daten haben, falls etwas schief geht, und dass Sie in der Lage sind, die Daten wiederherzustellen, falls erforderlich.
Überwachung: Überwachen Sie den Migrationprozess regelmäßig, um sicherzustellen, dass keine Daten verloren gehen und dass alle Prozesse wie geplant ablaufen.
Mit welcher Technoloigie kann man die Datenkonsistenz sicherstellen ?
Transaktionen: Durch die Verwendung von Transaktionen kann man die Integrität der Daten bei einer Migration sicherstellen, indem man sicherstellt, dass entweder alle Daten erfolgreich übertragen werden oder dass keine Daten übertragen werden, wenn ein Fehler auftritt.
Datenbank-Replikation: Durch die Verwendung von Datenbank-Replikation kann man eine exakte Kopie der Daten in Echtzeit erstellen, um sicherzustellen, dass bei einer Migration keine Daten verloren gehen.
Checksummen: Überprüfen Sie die Integrität der Daten während und nach der Migration durch Vergleich von Checksummen.
Hashing: Verwenden Sie Hash-Funktionen, um die Integrität der Daten zu überprüfen, indem Sie einen eindeutigen Hashwert für jede Datenquelle berechnen und vergleichen.
Änderungsprotokollierung: Protokollieren Sie jede Änderung an den Daten, um sicherzustellen, dass alle Änderungen während der Migration korrekt übertragen werden.
Der Ablauf einer Datenmigration in mehreren Schritten
Planung: Überprüfen Sie die Datenquelle und das Ziel, definieren Sie die Ziele und Anforderungen an die Migration und entwickeln Sie einen Zeitplan.
Vorbereitung: Bereiten Sie die Datenquelle und das Ziel auf die Migration vor, indem Sie Daten bereinigen, formatieren und validieren.
Übertragung: Übertragen Sie die Daten von der Quelle zum Ziel. Hier kann es erforderlich sein, dass Daten konvertiert werden, um das Zielformat zu unterstützen.
Validierung: Überprüfen Sie die Daten nach der Migration auf Vollständigkeit, Richtigkeit und Integrität.
Überwachung: Überwachen Sie die Migration, um sicherzustellen, dass alle Prozesse wie geplant ablaufen und dass keine Daten verloren gehen.
Abschluss: Abschließen Sie die Migration, indem Sie alle Dokumentationen und Protokolle aktualisieren und sicherstellen, dass das Ziel einwandfrei funktioniert.
Es ist wichtig, eine gründliche Planung und Vorbereitung durchzuführen, um sicherzustellen, dass die Migration reibungslos verläuft und dass alle Daten erfolgreich übertragen werden. Es kann auch hilfreich sein, ein erfahrenes Team oder einen externen Dienstleister hinzuzuziehen, um die Migration durchzuführen.

Archivieren oder Migrieren ?
Archivierung bezieht sich auf den Prozess des Speicherns von Daten, die nicht mehr aktiv genutzt werden, aber aus rechtlichen oder historischen Gründen aufbewahrt werden müssen. Oft werden archivierte Daten in medienfreundliche Formate konvertiert und auf sicheren Medien gespeichert, um sie vor Verlust oder Schäden zu schützen.
Migrieren beschreibt den Prozess des Übertragens von Daten von einem System oder einer Plattform auf eine andere. Dies wird oft durchgeführt, um aktuelle Technologien zu nutzen oder eine verbesserte Struktur der Daten zu schaffen. Während einer Migration müssen die Daten üblicherweise konvertiert und validiert werden, um sicherzustellen, dass sie im neuen System ordnungsgemäß funktionieren.
Ein Beispiel für ein vereinfachtes Vorgehen.
Die Toolchain ( Toolbox )
Eine Datenmigration in ein PLM-System (Product Lifecycle Management) bezieht sich auf den Prozess der Übertragung von Produkt- und Prozessdaten aus einem oder mehreren vorhandenen Systemen in das PLM-System. Hierbei handelt es sich um ein komplexes Verfahren, das eine sorgfältige Planung und eine umfassende Kenntnis der Datenquellen erfordert, um sicherzustellen, dass alle Daten korrekt und vollständig in das neue System migriert werden. Die Datenmigration kann durch verschiedene Tools und Techniken durchgeführt werden, einschließlich manueller Eingabe, ETL-Tools (Extract, Transform, Load) oder durch spezielle Softwareanwendungen, die für die Migration von Daten entwickelt wurden.
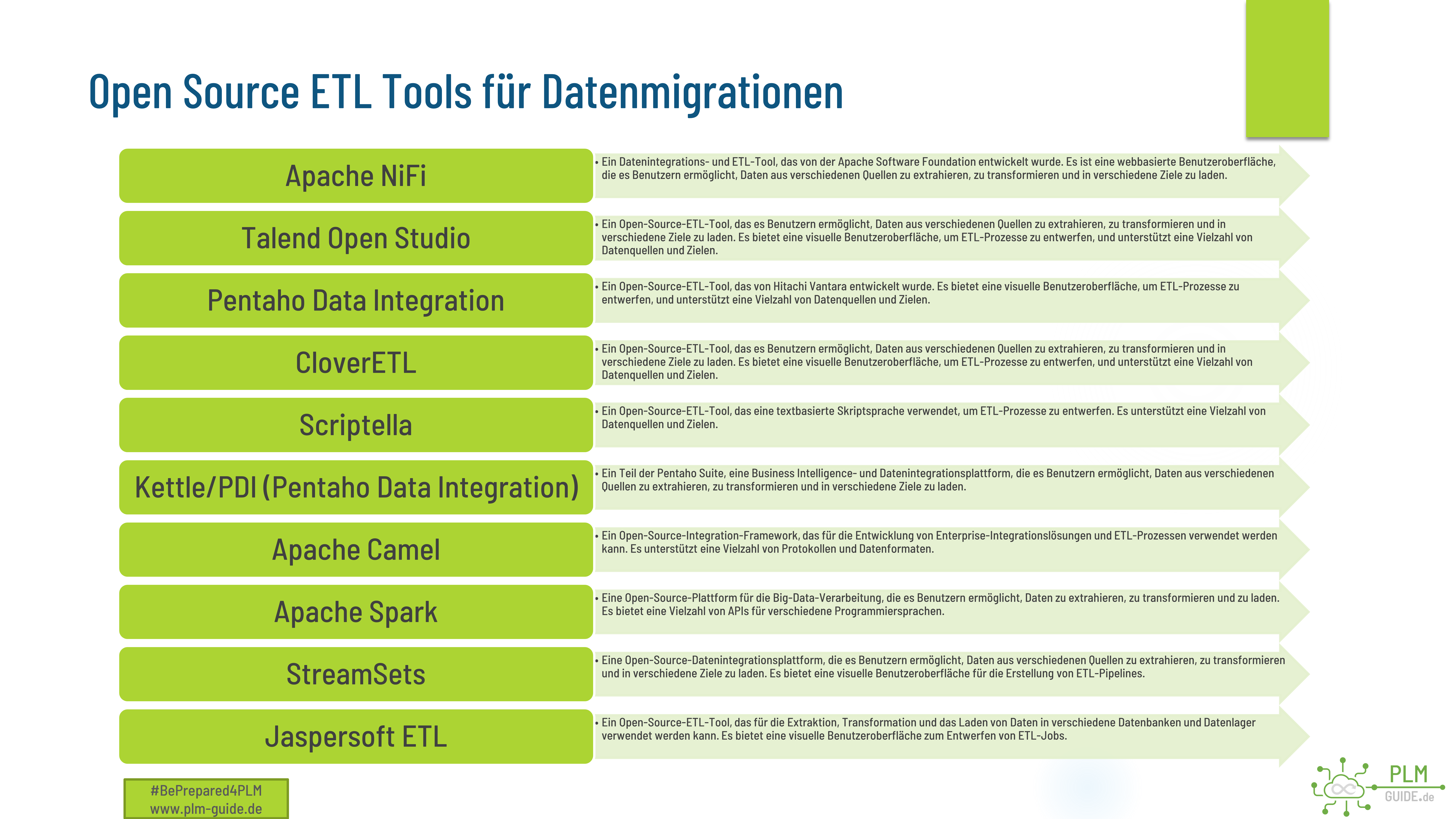
Open Source ETL Tools
Diese sind nur einige Beispiele für Open-Source-ETL-Tools. Es gibt viele weitere Tools und Frameworks, die kostenlos heruntergeladen und verwendet werden können, um ETL-Prozesse zu entwerfen und zu implementieren.
Muss es immer gleich ein ETL Tool sein ?
Obwohl ETL-Tools in der Regel sehr leistungsfähig und vielseitig sind, gibt es Situationen, in denen eine maßgeschneiderte, selbstgebaute Lösung sinnvoller sein kann. Hier sind einige Gründe, warum manchmal ein ETL-Tool nicht die beste Option ist:
Komplexität der Datenquellen: ETL-Tools können sehr gut mit strukturierten Daten umgehen. Wenn jedoch die Datenquellen komplexer sind, wie zum Beispiel unstrukturierte Daten, kann eine selbstgebaute Lösung besser geeignet sein.
Spezifische Anforderungen: Wenn spezielle Anforderungen an den Datenintegrationsprozess gestellt werden, die nicht durch ein ETL-Tool abgedeckt werden können, ist es möglicherweise besser, eine individuelle Lösung zu entwickeln.
Kosten: ETL-Tools können oft teuer sein, insbesondere wenn zusätzliche Lizenzen für bestimmte Funktionen erforderlich sind. In einigen Fällen kann es günstiger sein, eine selbstgebaute Lösung zu entwickeln, insbesondere wenn nur wenige Datenquellen und -ziele vorhanden sind.
Größe des Projekts: Für kleine Datenintegrationsprojekte kann die Verwendung eines ETL-Tools übertrieben sein. Eine kleine selbstgebaute Lösung kann einfacher, schneller und kosteneffektiver sein.
Erfahrung und Know-how: Wenn die IT-Abteilung über das notwendige Know-how und die Erfahrung verfügt, kann es einfacher sein, eine selbstgebaute Lösung zu entwickeln als sich in ein neues ETL-Tool einzuarbeiten.
Eine kleine selbstgebaute Lösung kann für kleine bis mittlere Datenintegrationsprojekte eine sinnvolle Option sein, insbesondere wenn die Anforderungen spezifisch sind und die Kosten im Auge behalten werden müssen. Es ist jedoch wichtig zu beachten, dass eine selbstgebaute Lösung möglicherweise nicht so leistungsfähig oder flexibel wie ein ETL-Tool ist und dass es bei größeren Projekten oft besser ist, auf ein ETL-Tool zurückzugreifen.
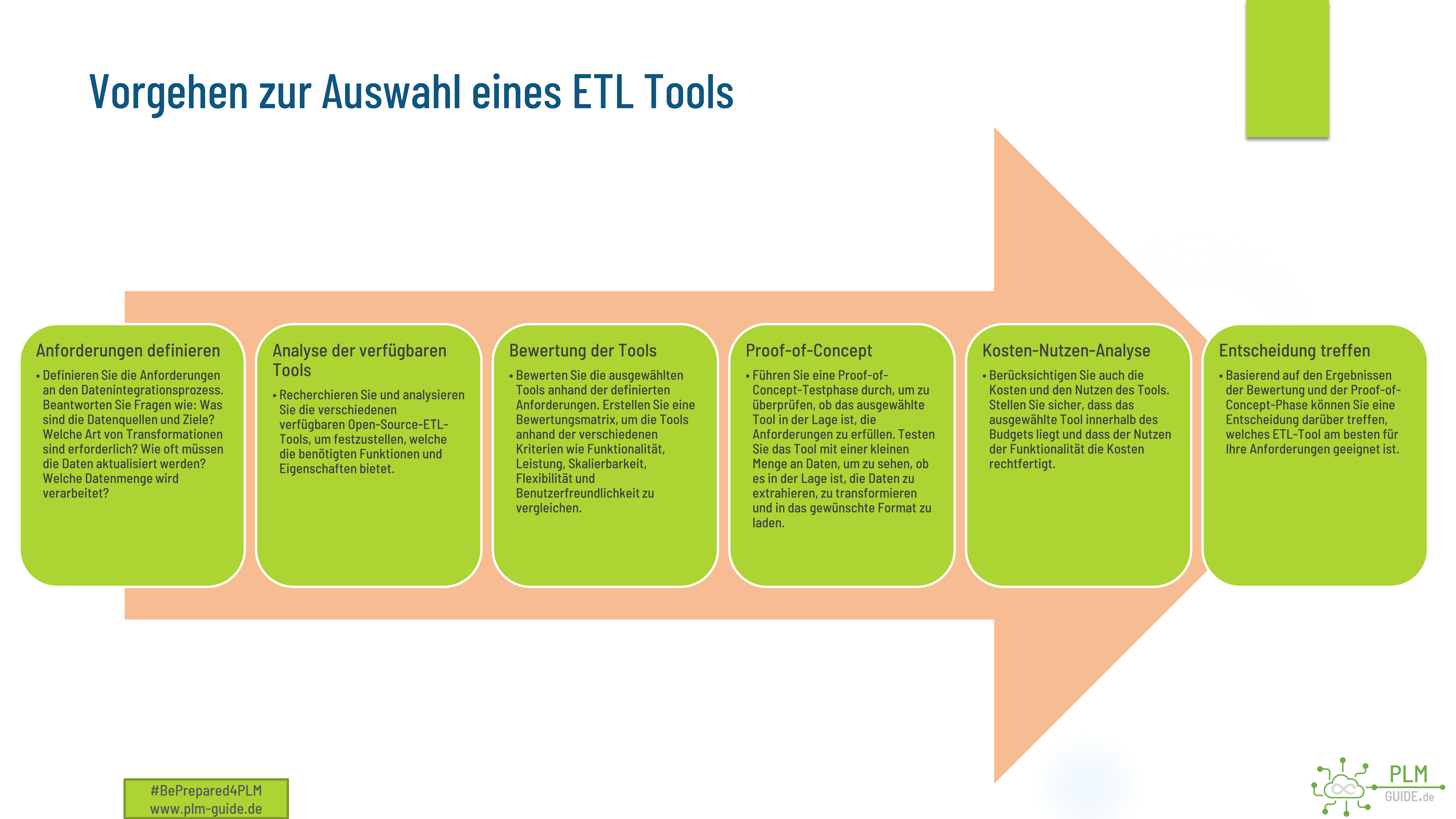
Vorgehen zur Auswahl eines ETL Tools
Die Wahl des richtigen Open-Source-ETL-Tools hängt von verschiedenen Faktoren ab, wie den spezifischen Anforderungen an den Datenintegrationsprozess, der Art der Datenquellen und -ziele, dem Umfang des Projekts und dem verfügbaren Budget.
Eine kleine selbsgebaute Toolchain mit SQlite und Python
Um eine Toolchain für die Datenmigration aus einem Filesystem und einer Datenbank zu erstellen, können wir verschiedene Schritte durchführen. Hier ist eine mögliche Lösung, die den gewünschten Anforderungen entspricht:
Dateisystem-Crawler: Wir können ein Python-Skript erstellen, das das Dateisystem durchsucht und alle Dateien im gewünschten Verzeichnis und seinen Unterordnern findet. Wir können Python-Module wie
osundos.pathverwenden, um auf das Dateisystem zuzugreifen. Für jeden gefundenen Dateipfad können wir die Dateiname, Größe, Erstelldatum und den Hashwert generieren.Hashwertgenerierung: Um die Hashwerte der Dateien zu generieren, können wir ein Python-Modul wie
hashlibverwenden, das verschiedene Hash-Algorithmen unterstützt, wie z.B. MD5 oder SHA-1. Wir können den Hashwert jedes Dateis berechnen und in unserem SQLite-Datenbank speichern.SQLite-Datenbank: Wir können eine SQLite-Datenbank erstellen, um alle Dateiinformationen zu speichern. Wir können Python-Module wie
sqlite3verwenden, um eine Verbindung zur Datenbank herzustellen und die benötigten Tabellen und Spalten zu erstellen. Wir können auch eine ID-Spalte hinzufügen, um jede Datei eindeutig zu identifizieren.Analyse auf doppelte Einträge: Um nach Duplikaten in der Datenbank zu suchen, können wir die Cosine-Similarity-Funktion verwenden, um den Ähnlichkeitsgrad zwischen den Hashwerten von zwei Dateien zu berechnen. Wir können dann alle Paare von Dateien in der Datenbank vergleichen und diejenigen finden, die einen Ähnlichkeitsgrad über einem bestimmten Schwellenwert haben. Wir können ein Python-Modul wie
numpyverwenden, um den Cosine-Similarity-Wert zu berechnen.Log-Erstellung: Schließlich können wir ein Protokoll erstellen, das alle gefundenen Duplikate und ihre Details enthält. Wir können ein Python-Modul wie
loggingverwenden, um die Protokolldatei zu erstellen und alle relevanten Informationen einzufügen.
import os
import hashlib
import sqlite3
import numpy as np
import logging
# Dateisystem-Crawler
def crawl_directory(root_dir):
for dirpath, dirnames, filenames in os.walk(root_dir):
for filename in filenames:
file_path = os.path.join(dirpath, filename)
size = os.path.getsize(file_path)
created_at = os.path.getctime(file_path)
hash_value = generate_hash(file_path)
yield (file_path, size, created_at, hash_value)
# Hashwertgenerierung
def generate_hash(file_path):
hash_alg = hashlib.md5()
with open(file_path, 'rb') as f:
while True:
data = f.read(65536)
if not data:
break
hash_alg.update(data)
return hash_alg.hexdigest()
# SQLite-Datenbank
def create_db(db_file):
conn = sqlite3.connect(db_file)
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS files
(id INTEGER PRIMARY KEY AUTOINCREMENT,
path TEXT UNIQUE,
size INTEGER,
created_at REAL,
hash_value TEXT)''')
conn.commit()
conn.close()
# Analyse auf doppelte Einträge
def find_duplicates(db_file, threshold=0.9):
conn = sqlite3.connect(db_file)
c = conn.cursor()
c.execute('SELECT id, hash_value FROM files')
rows = c.fetchall()
hashes = np.array([np.frombuffer(bytes.fromhex(row[1]), dtype=np.uint8) for row in rows])
similarities = np.dot(hashes, hashes.T) / (np.linalg.norm(hashes, axis=1) * np.linalg.norm(hashes, axis=1)[:, np.newaxis])
np.fill_diagonal(similarities, 0)
duplicates = np.argwhere(similarities > threshold)
for pair in duplicates:
file1 = rows[pair[0]]
file2 = rows[pair[1]]
logging.info(f'Duplicate found: {file1[0]} ({file1[1]}) and {file2[0]} ({file2[1]})')
conn.close()
# Log-Erstellung
def setup_logging(log_file):
logging.basicConfig(filename=log_file, level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
if __name__ == '__main__':
root_dir = '/path/to/root/directory'
db_file = 'file_info.db'
log_file = 'migration.log'
setup_logging(log_file)
create_db(db_file)
conn = sqlite3.connect(db_file)
c = conn.cursor()
c.execute('BEGIN TRANSACTION')
for file_info in crawl_directory(root_dir):
try:
c.execute('INSERT INTO files (path, size, created_at, hash_value) VALUES (?, ?, ?, ?)', file_info)
except sqlite3.IntegrityError:
logging.warning(f'File {file_info[0]} already exists in database')
c.execute('COMMIT')
conn.close()
find_duplicates(db_file)
Das Skript geht davon aus, dass das zu durchsuchende Root-Verzeichnis in der root_dir-Variable definiert ist. Es erstellt eine SQLite-Datenbank mit dem Dateinamen file_info.db und eine Protokol

Texte und Strings vergleichen und bereinigen.
Die genannten Methoden zum Vergleich von Strings können bei der Datenbereinigung sehr hilfreich sein. Oftmals kann es bei der Dateneingabe oder Datenübertragung zu Tippfehlern oder anderen Fehlern kommen, die dazu führen, dass gleiche oder ähnliche Zeichenfolgen in einer Datenbank unterschiedlich gespeichert werden. Durch den Einsatz dieser Methoden können solche Fehler identifiziert und korrigiert werden, um die Daten in einer Datenbank zu bereinigen und zu konsolidieren.