
Enterprise Search Engine im PLM integrieren
Um die Effizienz und Produktivität innerhalb des Unternehmens zu steigern, kann eine Enterprise Search Engine unterstüzen indem sie den Mitarbeitern eine schnellere und einfachere Möglichkeit bietet, auf relevante Informationen zuzugreifen und diese zu nutzen.
Einleitung
Eine Enterprise Search Engine ist eine Suchmaschine, die speziell für den Einsatz in Unternehmen entwickelt wurde, um eine effektive und umfassende Suche nach Informationen und Daten innerhalb des Unternehmens zu ermöglichen. Im Gegensatz zu öffentlichen Suchmaschinen wie Google oder Bing, die das gesamte Internet durchsuchen, ist eine Enterprise Search Engine darauf ausgerichtet, nur die Informationen und Datenquellen zu durchsuchen, die im Unternehmen vorhanden sind.
Eine Enterprise Search Engine kann auf verschiedenen Datenquellen zugreifen, wie beispielsweise interne Websites, Dateien, E-Mails, Dokumente, CRM-Systeme, ERP-Systeme oder andere Unternehmensanwendungen. Die Ergebnisse werden dann in einer übersichtlichen und intuitiven Art und Weise präsentiert, die es den Benutzern erleichtert, relevante Informationen zu finden und zu nutzen.
Eine Enterprise Search Engine kann dabei helfen, die Effizienz und Produktivität innerhalb des Unternehmens zu steigern, indem sie den Mitarbeitern eine schnellere und einfachere Möglichkeit bietet, auf relevante Informationen zuzugreifen und diese zu nutzen.
Aufbau und Technologie
Eine Enterprise Search Engine besteht im Wesentlichen aus drei Komponenten: der Datenquellenintegration, dem Suchindex und der Suchanfrageverarbeitung.
Die Datenquellenintegration ermöglicht es der Enterprise Search Engine, auf eine Vielzahl von internen und externen Datenquellen zuzugreifen, einschließlich interner Websites, Dateiserver, E-Mail-Server, CRM-Systeme, ERP-Systeme, Datenbanken und anderen Unternehmensanwendungen. Hierbei müssen unterschiedliche Schnittstellen und Protokolle unterstützt werden, um eine effektive Integration zu gewährleisten.
Die Datenquellen werden dann von der Enterprise Search Engine indexiert, um die Suche zu beschleunigen. Der Suchindex ist eine spezielle Datenbank, die es der Suchmaschine ermöglicht, schnell auf relevante Informationen zuzugreifen und Suchanfragen effizient zu verarbeiten. Der Index wird regelmäßig aktualisiert, um sicherzustellen, dass die neuesten Informationen verfügbar sind.
Die Suchanfrageverarbeitung ist die Komponente, die dafür verantwortlich ist, die Benutzeranfragen zu interpretieren und die relevantesten Ergebnisse zurückzugeben. Die Enterprise Search Engine verwendet eine Kombination aus natürlicher Sprachverarbeitung, semantischen Analysen und Ranking-Algorithmen, um die Suchanfragen zu verstehen und passende Ergebnisse zu liefern. Die Ergebnisse werden dann aufbereitet und präsentiert, um die Benutzererfahrung zu optimieren.
Darüber hinaus kann eine Enterprise Search Engine auch Funktionen wie Vorschläge für ähnliche oder verwandte Suchbegriffe, Filtern und Sortieren von Ergebnissen sowie das Erstellen von Alerts und Berichten anbieten.
Unentdeckte Potentiale
In der heutigen Geschäftswelt ist der Zugang zu Informationen von entscheidender Bedeutung für den Erfolg eines Unternehmens. Unternehmen müssen in der Lage sein, schnell auf relevante Informationen zuzugreifen, um fundierte Entscheidungen zu treffen und ihre Wettbewerbsfähigkeit zu erhalten. Eine Möglichkeit, dies zu erreichen, ist die Verwendung von Webcrawlern, die es Unternehmen ermöglichen, interne Informationen schnell zu sammeln und zu durchsuchen.
Glücklicherweise sind heute im Open-Source-Umfeld viele Technologien verfügbar, die es Unternehmen ermöglichen, ihren eigenen internen Webcrawler zu bauen. Diese Technologien bieten eine Vielzahl von Funktionen, die es Benutzern ermöglichen, Inhalte aus verschiedenen Quellen zu extrahieren, zu durchsuchen und zu analysieren. Einige Beispiele für Open-Source-Webcrawlertechnologien sind Apache Nutch, Apache ManifoldCF, Scrapy und Heritrix.
Die Vorteile der Verwendung eines internen Webcrawlers sind zahlreich. Zum einen können Unternehmen Zeit und Kosten sparen, da sie nicht auf externe Dienstleister angewiesen sind, um relevante Informationen zu sammeln und zu durchsuchen. Zum anderen können Unternehmen ihre Suchergebnisse genau anpassen, um nur die relevanten Informationen zu erhalten, die sie benötigen, ohne von anderen Inhalten abgelenkt zu werden.
Ein weiterer Vorteil ist, dass Unternehmen ihre eigenen internen Richtlinien und Vorschriften einhalten können, um sicherzustellen, dass sie nur auf Daten zugreifen, auf die sie zugreifen dürfen. Ein interner Webcrawler kann auch die Sicherheit erhöhen, da er keine vertraulichen Informationen außerhalb des Unternehmens freigibt.
Trotz all dieser Vorteile sind vielen Unternehmen die zur Verfügung stehenden Technologien nicht bekannt, und sie nutzen daher nicht das volle Potenzial, das interne Webcrawlertechnologien bieten. Durch die Umsetzung eines internen Webcrawlers können Unternehmen ihre Suche nach relevanten Informationen rationalisieren, ihre Wettbewerbsfähigkeit verbessern und ihre Geschäftsentscheidungen auf einer soliden Grundlage treffen.
Enterprise Search Engine auf Basis von Open Source Lösungen
Eine Enterprise Search Engine kann aus verschiedenen Open-Source-Komponenten aufgebaut werden, die zusammen eine leistungsstarke und kostengünstige Lösung bieten. Ein Beispiel hierfür ist die Integration von Apache Solr und Apache Nutch.
Apache Solr ist ein Suchserver, der es Benutzern ermöglicht, schnell und einfach nach Inhalten in einer Vielzahl von Datenquellen zu suchen. Es ist in Java geschrieben und basiert auf der Apache Lucene-Bibliothek, die eine leistungsstarke Volltextsuche bietet. Solr bietet eine Reihe von Funktionen wie Faceting, Filtern und Sortieren von Ergebnissen sowie Highlighting.
Apache Nutch ist ein Crawler-Framework, das es Benutzern ermöglicht, Webinhalte zu extrahieren und zu durchsuchen. Es ist ebenfalls in Java geschrieben und basiert auf der Apache Hadoop-Bibliothek, die eine skalierbare verteilte Datenverarbeitung ermöglicht. Nutch bietet eine Vielzahl von Plugins, die es ermöglichen, verschiedene Arten von Webinhalten zu extrahieren und zu verarbeiten.
Die Integration von Solr und Nutch ermöglicht es Benutzern, eine leistungsstarke Enterprise Search Engine aufzubauen, die in der Lage ist, interne und externe Datenquellen zu durchsuchen. Nutch kann verwendet werden, um Webinhalte zu extrahieren und zu indexieren, während Solr die Suche durchführt und die Ergebnisse präsentiert.
Die Integration von Solr und Nutch kann auf verschiedene Arten erfolgen. Eine Möglichkeit besteht darin, Nutch so zu konfigurieren, dass es Daten an Solr sendet, sobald sie extrahiert wurden. Solr kann dann die empfangenen Daten indexieren und die Suche ausführen. Eine andere Möglichkeit besteht darin, Solr als Crawler zu verwenden, indem man Solr so konfiguriert, dass es Webinhalte extrahiert und indexiert.
Die Integration von Solr und Nutch erfordert in der Regel eine gewisse technische Erfahrung, da beide Komponenten konfiguriert und angepasst werden müssen, um die spezifischen Anforderungen des Unternehmens zu erfüllen. Es gibt jedoch auch Unternehmen, die spezielle Distributionen von Solr und Nutch anbieten, die vorkonfiguriert und einfach zu installieren sind.
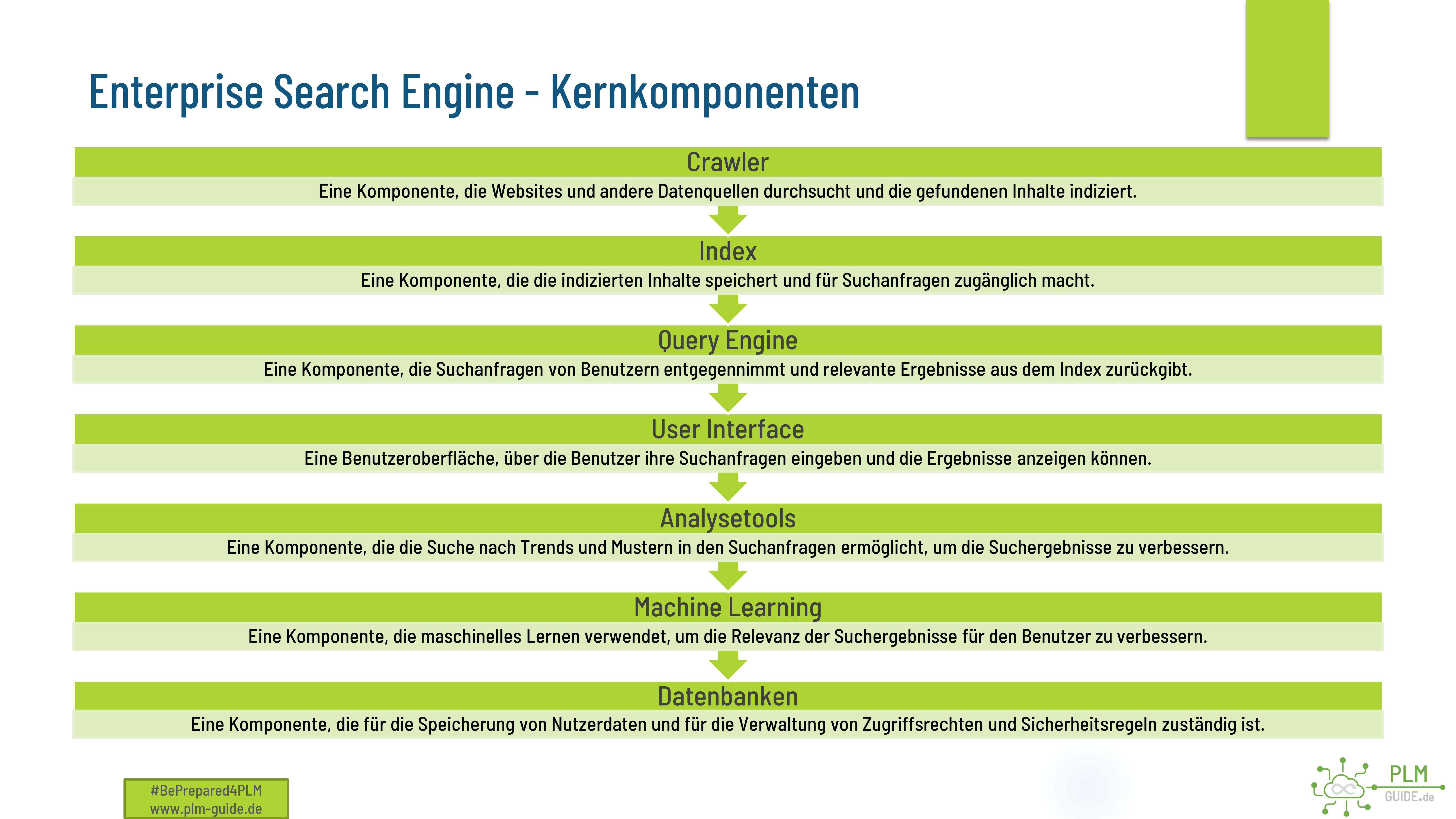
Ein Beispiel für den Aufbau einer Enterprise Search Engine
Durch die Integration dieser Komponenten können Unternehmen eine leistungsstarke Enterprise Search Engine aufbauen, die ihre internen Datenquellen durchsuchen und relevante Informationen für ihre Mitarbeiter bereitstellen kann.
Open Source Crawler für den Aufbau einer Enterprise Search Engine
Es gibt eine Vielzahl von Open-Source-Crawlern, die für den Zweck einer Enterprise Search Engine eingesetzt werden können. Einige weitere Beispiele sind:
Apache ManifoldCF: Ein Crawler-Framework, das es Benutzern ermöglicht, Inhalte aus verschiedenen Quellen zu extrahieren und zu durchsuchen. Es unterstützt eine Vielzahl von Datenquellen, einschließlich Dateiservern, Datenbanken, E-Mail-Servern und Content-Management-Systemen.
Scrapy: Ein Python-basiertes Web-Crawling-Framework, das es Benutzern ermöglicht, Webinhalte zu extrahieren und zu durchsuchen. Es unterstützt das Extrahieren von strukturierten Daten aus Websites und bietet eine Vielzahl von Funktionen wie automatisches Throttling und das Umgang mit Cookies.
Heritrix: Ein Java-basiertes Web-Crawling-Framework, das von der Internet Archive entwickelt wurde. Es ist speziell auf die Archivierung von Webinhalten ausgerichtet und unterstützt eine Vielzahl von Datenquellen und Protokollen.
Web Harvest: Ein Java-basiertes Web-Crawling-Framework, das es Benutzern ermöglicht, Webinhalte zu extrahieren und zu durchsuchen. Es bietet eine Vielzahl von Funktionen wie HTML- und XML-Extraktion, XPath-Unterstützung und Konfiguration durch XML-Dateien.
Norconex HTTP Collector: Ein Java-basiertes Web-Crawling-Framework, das es Benutzern ermöglicht, Inhalte von Websites und anderen HTTP-basierten Quellen zu extrahieren und zu durchsuchen. Es unterstützt das Extrahieren von strukturierten Daten und bietet Funktionen wie Konfiguration durch XML-Dateien und das Umgang mit Duplikaten.
- BeautifulSoup: Ein Python-basiertes Web-Crawling-Framework, das es Benutzern ermöglicht, Webinhalte zu extrahieren und zu durchsuchen. Es ist bekannt für seine einfache Handhabung von HTML- und XML-Code und bietet eine Vielzahl von Funktionen wie das Finden von HTML-Tags und -Attributen.
Diese Open-Source-Crawler bieten eine Vielzahl von Funktionen und unterstützen verschiedene Datenquellen und Protokolle, was es Benutzern ermöglicht, eine auf ihre spezifischen Anforderungen zugeschnittene Enterprise Search Engine zu erstellen.
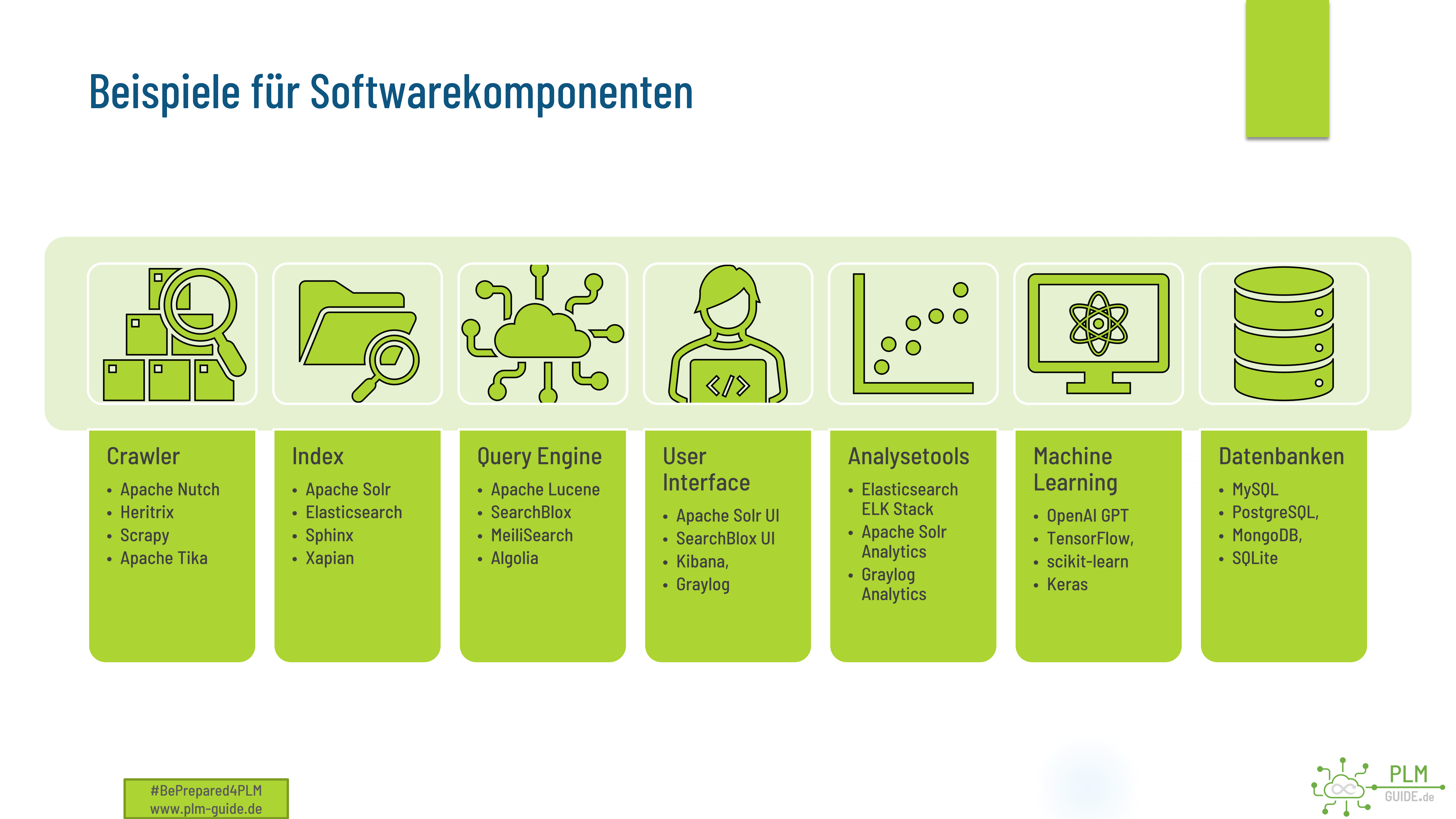
Beispiele für Softwarekomponeten
Diese Beispiele sind nur eine kleine Auswahl an verfügbaren Optionen im Open-Source-Bereich, es gibt viele weitere Lösungen, die für jede Komponente verwendet werden können und für die eigenen Anforderungen ausgelegt werden.
Effiziente Web-APIs zur Vermeidung doppelter Anlagen bei der Daten-Erstellung mit Enterprise Search Engines
In der heutigen Zeit ist die Verwaltung und Analyse von Daten eine unverzichtbare Komponente für jedes Unternehmen. Eine der am häufigsten verwendeten Methoden, um Daten zu finden und zu organisieren, ist die Verwendung von Suchmaschinen. Suchmaschinen sind jedoch nicht nur nützlich, um Daten zu finden, sondern können auch bei der Erstellung von Daten unterstützen, indem sie über eine bereitgestellte Web-API die Vermeidung von Doppelteingaben und Redundanzen ermöglichen.
Durch die Nutzung der Web-API können Entwickler sicherstellen, dass die eingegebenen Daten in der Datenbank bereits vorhanden sind. Dies minimiert die Wahrscheinlichkeit von doppelten Eingaben und sorgt dafür, dass die Datenbank sauber und organisiert bleibt. Durch die Verwendung von Suchmaschinen-APIs können Unternehmen sicherstellen, dass ihre Daten effizient erstellt und organisiert werden.
Einige kommerzielle Suchmaschinen bieten auch die Indizierung von 3D-Daten an, um Geometrieinformationen abzugleichen. Mit der BREP (Boundary Representation) Technologie wird es möglich, geometrische Informationen abzugleichen und somit zu vermeiden, dass redundante Daten in der Datenbank vorhanden sind. Die Indizierung von 3D-Daten ist insbesondere in der Produktentwicklung und im Engineering von großer Bedeutung, da sie den Entwicklungsprozess beschleunigen und die Genauigkeit verbessern kann.
Indizierte Daten sind auch eine hervorragende Grundlage für Datenanalysen im Bereich Data Science. Indem Unternehmen ihre Daten effektiv indizieren, können sie leichter Muster und Trends in ihren Daten erkennen. Dies ermöglicht es Unternehmen, bessere Entscheidungen zu treffen und ihre Geschäftsprozesse zu optimieren.
Zum Schluss noch ein kleines Beispiel wie eine Website mit Apache Solr indiziert werden kann.
# Schritt 1: Apache Nutch herunterladen und extrahieren
wget https://www-eu.apache.org/dist/nutch/latest/apache-nutch-1.18-bin.tar.gz
tar -xvf apache-nutch-1.18-bin.tar.gz
cd apache-nutch-1.18
# Schritt 2: Nutch-Konfiguration anpassen
cp conf/nutch-site.xml.template conf/nutch-site.xml
echo 'export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64' >> conf/nutch-env.sh
# Schritt 3: Solr-Konfiguration anpassen
cd conf
cp solr-1.4/conf/* solr/conf/
# Schritt 4: Solr-Index erstellen
cd ../runtime/local
mkdir -p solr/nutch
bin/nutch solrindex http://localhost:8983/solr/nutch crawl/crawldb -linkdb crawl/linkdb crawl/segments/*
# Schritt 5: Solr-Suche testen
cd ../../..
bin/nutch solrsearch "my search query"
Dieses Skript lädt zunächst Nutch und Solr herunter und extrahiert sie in den entsprechenden Verzeichnissen. Anschließend werden die Konfigurationsdateien von Nutch und Solr angepasst, um sicherzustellen, dass sie ordnungsgemäß funktionieren.
Dann wird ein Solr-Index erstellt, indem Nutch verwendet wird, um die Website zu durchsuchen und die Inhalte in Solr zu indexieren. Schließlich kann die Suche in Solr getestet werden, indem ein Suchbegriff in Nutch eingegeben wird.
Beachten Sie, dass dieses Beispiel-Skript an Ihre spezifischen Anforderungen angepasst werden muss, einschließlich der anzupassenden Konfigurationsdateien und der zu durchsuchenden Website.
Ein Beispiel-Skript, das Scrapy verwendet, um ein Dateisystem zu durchsuchen
Scrapy ist eine leistungsstarke Web-Crawling- und Scraping-Engine, die in Python geschrieben wurde. Sie kann jedoch auch für andere Zwecke verwendet werden, wie z.B. zum Durchsuchen von Dateisystemen.
Hier ist ein Beispiel-Skript, das Scrapy verwendet, um ein Dateisystem zu durchsuchen und die Ergebnisse in einer Textdatei zu speichern:
import os
from scrapy.item import Item, Field
from scrapy.spiders import Spider
class FileItem(Item):
path = Field()
size = Field()
class FileSystemSpider(Spider):
name = "file_system"
start_urls = ["file:///home/user/Documents"]
def parse(self, response):
for root, dirs, files in os.walk(response.url):
for file in files:
file_path = os.path.join(root, file)
file_size = os.path.getsize(file_path)
yield FileItem(path=file_path, size=file_size)
In diesem Skript wird zunächst eine Item-Klasse definiert, um die Daten für jede gefundene Datei zu speichern. Dann wird eine Spider-Klasse definiert, die das Dateisystem durchsucht und die Ergebnisse in Scrapy-Items umwandelt.
Der Start-URL für die Spider ist das Wurzelverzeichnis des Dateisystems. Die parse()-Methode wird für jede gefundene Datei aufgerufen, und es werden die entsprechenden Informationen wie Pfad und Größe gesammelt. Diese Informationen werden dann in Instanzen der FileItem-Klasse gespeichert und von der Spider ausgegeben.
Um das Skript auszuführen, können Sie die Scrapy-Konsole verwenden:
scrapy runspider file_system_spider.py -o files.csv
Dieses Skript durchsucht das Dateisystem und speichert die Ergebnisse in einer CSV-Datei mit dem Namen files.csv. Beachten Sie, dass das Skript an Ihre spezifischen Anforderungen angepasst werden muss, einschließlich der zu durchsuchenden Verzeichnisse und der zu verwendenden Dateiformate.
Dies ist ein kleines Beispiel und kann in alle Richtungen erweitert werden und skaliert werden :
- Dublettenverleich
- OCR und Dokumentenindizierung
- Bildererkennung
- Strukturanalyse
- Monitoring


